巴菲特说过…
傻子才会分散投资
我看过不少“股票网红”说过这句话
他们说散户应该集中火力在2-3只你非常了解的公司上
他们也说散户没有那个能力和时间去对那么多公司做研究,这点我是非常认同的
散户有的知识其实很有限,就算他们认为他们有,其实也只是皮毛,毕竟分析这门学问需要专业知识和经验
其实什么是风险?
学术上来说,风险就是价格的标准差(standard deviation),高波动的就被归类为高风险,低波动就被归类为低风险
业内常用的夏普比率(Sharpe ratio)和现代组合理论(Markowitz’s Modern Portfolio Theory)都是用价格的标准差来衡量风险
也有另一派市场人士认为标准差不能很好的衡量风险
这派有的是著名的Howard Marks和Nassim Taleb
他们的想法是风险应该是爆仓的风险,输光的风险
当然要以这个想法来衡量是比较难定量的
我觉得双方都有他们很强的观点,可是目前为止我还没发现如何去定量爆仓的风险
这编文章我还是以标准差来衡量风险
分散投资如何降低风险?
我们来比较两个Portfolio
Portfolio A (2-3 只股票)
Portfolio B (20-30 只股票)
哪个portfolio有更高的风险呢?
很明显是Portfolio B (前提是要很好的分散)
Portfolio B要大额亏损的前提是要20-30只股票全部都下跌
透过分散投资,你除去了个别公司的风险
把风险降低至接近你不可控制的市场风险
我的回酬很高,我才不在乎
有些人可能会说
我的回酬年化20%,我才不理什么标准差
在绝对数目上来看真的很好
可是在投资界离,有一个不多散户知道的标的
那就是夏普比率
夏普比率测量的是,你冒了多大风险来换取回酬
年化20%,可是50%的波动性?
还是年化10%,可是5%的波动性?
高夏普比率的意思是你在一个单位的风险时,得到更高的回酬
毕竟要提高回酬的方式就是提高杠杆,也就是提高风险
这不难办到,难的是如何在同等风险得到更高回酬
屁话少说,放码过来
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
stock_data = pd.read_csv('A.csv',parse_dates=['Datetime'])
stock_data['Changes_Next_Year'] = stock_data.groupby('Code')['Change'].shift(-1)
stock_data.dropna(subset=['Changes_Next_Year'],inplace=False)
def simulate(stock_data, NumberOfShares):
'''
Randomly select n number of shares
and check their annual performance
'''
stock_data = stock_data.groupby(['Datetime']).sample(NumberOfShares)
output = pd.DataFrame()
stock_data['Code'] += ' '
stock_data_groupby = stock_data.groupby('Datetime')
output['Shares_bought'] = stock_data_groupby['Code'].sum()
output['Number of shares'] = stock_data_groupby.size()
output['Average gains'] = stock_data_groupby['Changes_Next_Year'].mean()
output['Average gains'].replace(np.inf, 0, inplace=True)
output['Capital'] = 0
output = output.dropna()
output['Capital'] = (output['Average gains']+1.0).cumprod()
output['Average gains'] = output['Average gains']*100.0
return output['Average gains'].mean(), output['Average gains'].std()这function return的是平均年化回酬和平均标准差
下面给个例子
print(simulate(stock_data, 2))(17.10975895157977, 36.62720358784172)现在我们有了simulate的function
现在要做的就是模拟几十次,然后尝试不同的股票数目
最后把数据可视化
def run(stock_data,NumberOfShares):
ret = 0
std = 0
iteration = 60
for i in range(1,iteration + 1):
r,s = simulate(stock_data,NumberOfShares)
ret += r
std += s
return ret/(iteration), std/(iteration)
# simulate from 1 stock to 100 stocks portfolio
stdev = []
ret = []
for i in range(1,100):
tempr, temps = run(stock_data,i)
stdev.append(temps)
ret.append(tempr)
# visualize the data
fig, ax1 = plt.subplots(figsize=(10,5))
plt.style.use('seaborn')
ax2 = ax1.twinx()
ax1.plot(stdev, 'darkgreen',linestyle = '-', marker = '.', alpha = 0.5)
ax2.plot(ret, 'darkblue', linestyle = '-', marker = '.', alpha = 0.5)
ax1.set_xlabel('Number of Shares in portfolio')
ax1.set_ylabel('Standard Deviation of Returns', color='darkgreen')
ax2.set_ylabel('Average Compounded Annual Growth Rate', color='darkblue')
ax1.grid(False)
ax2.grid(False)
plt.show()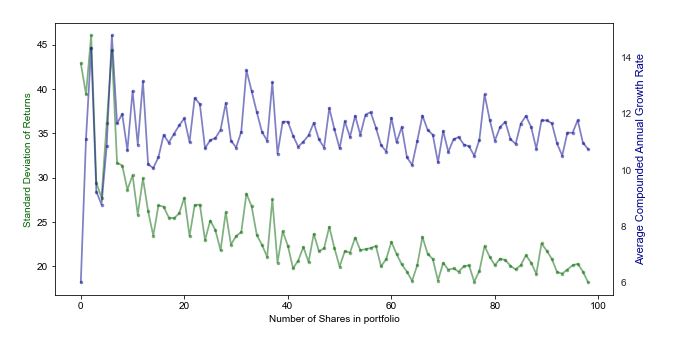
结论
- 拥有越多只股票,你的portfolio波动性会降低(风险)
- 有趣的是,这也会稳定你的回酬
- 以上回酬的股票是随机选择的,实战中我们应该分散在没有相关性的资产上
例如,如果你已经持有FAANG,你不需要再买入更多的科技股 - 一旦达到一定数目的股票(10-15),回酬与风险都会稳定下来
换句话说,持有20只股票和持有40只股票的风险与回酬是差不多的 - 散户要买入10-15只股票是不实际的
散户的资本和知识都是瓶颈
加上散户自己做的“功课”并不能保证是没有错误的 - 一个实际的分散投资做法是买入基金(unit trust, mutual fund, 政府基金)或ETF
这些都是高度分散的投资
可是这恐怕不是喜欢冒险的人的选择
傻子才会分散投资。可是把自己当成傻子才是最安全的